

一、服务器规划
本次部署有5台服务器,namenode主备两台,datanode三台,具体规划如下表:
| 服务器IP | 域名 | 角色 | 备注 |
|---|---|---|---|
| 192.168.31.218 | HD01.MYHDFS.COM | namenode,resourcemanager | |
| 192.168.31.153 | HD02.MYHDFS.COM | datanoade,nodemanager,zoomkeeper,journal | |
| 192.168.31.236 | HD03.MYHDFS.COM | datanode,nodemanager,zoomkeeper,journal | |
| 192.168.31.61 | HD04.MYHDFS.COM | datanode,nodemanager,zoomkeeper,journal | |
| 192.168.31.11 | HD05.MYHDFS.COM | namenode,resourcemanager |
二、前置配置
1、主机host配置
在每台主机/etc/hosts 添加一下hosts 绑定,方便后面用主机访问
192.168.31.218 HD01 HD01.MYHDFS.COM
192.168.31.153 HD02 HD02.MYHDFS.COM
192.168.31.236 HD03 HD03.MYHDFS.COM
192.168.31.61 HD04 HD04.MYHDFS.COM
192.168.31.11 HD05 HD05.MYHDFS.COM
2、创建hadoop用户
useradd hadoop
echo "hadoop" | passwd --stdin hadoop
# 将hadoop添加到root组
usermode -g root hadoop
3、配置ssh免密码登陆
# 在每台主机都进行如下操作,以HD01为例
su - hadoop
ssh-keygen
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@HD01
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@HD02
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@HD03
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@HD04
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@HD05
4、安装并配置java环境
wget https://tool-box.oss-cn-hangzhou.aliyuncs.com/jdk-8u111-linux-x64.tar.gz
tar zxvf jdk-8u111-linux-x64.tar.gz -C /usr/local
cat >> /etc/profile << EOF
export JAVA_HOME=/usr/local/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH={JAVA_HOME}/bin:$PATH
EOF
source /etc/profile
三、ZOOKEEPER安装
1、下载安装
su - hadoop
wget https://tool-box.oss-cn-hangzhou.aliyuncs.com/apache-zookeeper-3.5.6-bin.tar.gz
tar zxvf apache-zookeeper-3.5.6-bin.tar.gz -C /home/hadoop/
ln -s apache-zookeeper-3.5.6-bin zookeeper
mkdir -p /home/hadoop/zookeeper/data
mkdir -p /home/hadoop/zookeeper/log
修改zoo.cfg 如下:
echo >> /home/hadoop/zookeeper/conf/zoo.cfg << EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/zookeeper/data
dataLogDir=/home/hadoop/zookeeper/log
clientPort=2181
server.1=HD02:2888:3888
server.2=HD03:2888:3888
server.3=HD04:2888:3888
EOF
2、配置ID
# HD02上
echo 1 > /home/hadoop/zookeeper/data/myid
# HD03上
echo 2 > /home/hadoop/zookeeper/data/myid
# HD04上
echo 3 > /home/hadoop/zookeeper/data/myid
3、启动zookeeper集群
# HD02上
su - hadoop
/home/hadoop/zookeeper/bin/zkServer.sh start
# 查看状态
/home/hadoop/zookeeper/bin/zkServer.sh status
# HD03上
su - hadoop
/home/hadoop/zookeeper/bin/zkServer.sh start
# 查看状态
/home/hadoop/zookeeper/bin/zkServer.sh status
# HD04上
su - hadoop
/home/hadoop/zookeeper/bin/zkServer.sh start
# 查看状态
/home/hadoop/zookeeper/bin/zkServer.sh status
四、安装部署HADOOP
1、下载安装(只在HD01)
su - haddop
wget https://tool-box.oss-cn-hangzhou.aliyuncs.com/hadoop-3.1.3.tar.gz
tar zxvf hadoop-3.1.3.tar.gz -C /home/hadoop/
ln -s hadoop-3.1.3 hadoop
2、在namenode(HD01)主节点配置
2.1 配置core-site.yml
cat > /home/hadoop/hadoop/etc/hadoop/core-site.xml < EOF
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>HD02:2181,HD03:2181,HD04:2181</value>
</property>
</configuration>
EOF
2.2 配置 hdfs-site.yml
cat > /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml < EOF
<configuration>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是hdfs01,hdfs05 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>HD01,HD05</value>
</property>
<!-- hdfs01的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.HD01</name>
<value>HD01:9000</value>
</property>
<!-- hdfs05的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.HD05</name>
<value>HD05:9000</value>
</property>
<!-- hdfs01的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.HD01</name>
<value>HD01:50070</value>
</property>
<!-- hdfs05的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.HD05</name>
<value>HD05:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://HD02:8485;HD03:8485;HD04:8485/mycluster</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/mnt/disk01,/home/hadoop/mnt/disk02,/home/hadoop/mnt/disk03,/home/hadoop/mnt/disk04,/home/hadoop/mnt/disk05</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop/data/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
shell(/bin/true)
</value>
</property>
<!-- 设置副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置块大小-->
<property>
<name>dfs.block.size</name>
<value>64M</value>
</property>
</configuration>
EOF
2.3 配置 yarn-site.yml
cat > /home/hadoop/hadoop/etc/hadoop/yarn-site.xml < EOF
<configuration>
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>HD01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>HD05</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>HD02:2181,HD03:2181,HD04:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
EOF
2.4 配置worker
cat >> /home/hadoop/hadoop/etc/hadoop/worker << EOF
HD02
HD03
HD04
EOF
2.5 初始化HA在zookeeper上的状态(HD01上执行)
su - hadoop
/home/hadoop/hadoop/bin/hdfs zkfc -formatZK
3、将hadoop 同步到其他4台主机
scp -r /home/hadoop/hadoop-3.13 hadoop@HD02:~/
scp -r /home/hadoop/hadoop-3.13 hadoop@HD03:~/
scp -r /home/hadoop/hadoop-3.13 hadoop@HD04:~/
scp -r /home/hadoop/hadoop-3.13 hadoop@HD05:~/
4、在HD02,HD03,HD04上分别启动journal
/home/hadoop/hadoop-3.1.3/sbin/hadoop-daemon.sh start journalnode
# 用jps命令查看状态
[hadoop@HD02 ~]$ jps
14374 Jps
9801 JournalNode
8410 QuorumPeerMain
5、初始化namenode
# 在HD01(主namenode)
su - hadoop
/home/hadoop/hadoop/bin/hdfs namenode -format mycluster
# 在HD05(备namenode)
su - hadoop
/home/hadoop/hadoop/bin/hdfs namenode -bootstrapStandby
6、启动namenode、datanode
# 在HD01上
/home/hadoop/hadoop/sbin/start-dfs.sh
7、启动reourcemanager、nodemanager
# 在HD01上
/home/hadoop/hadoop/sbin/start-yarn.sh
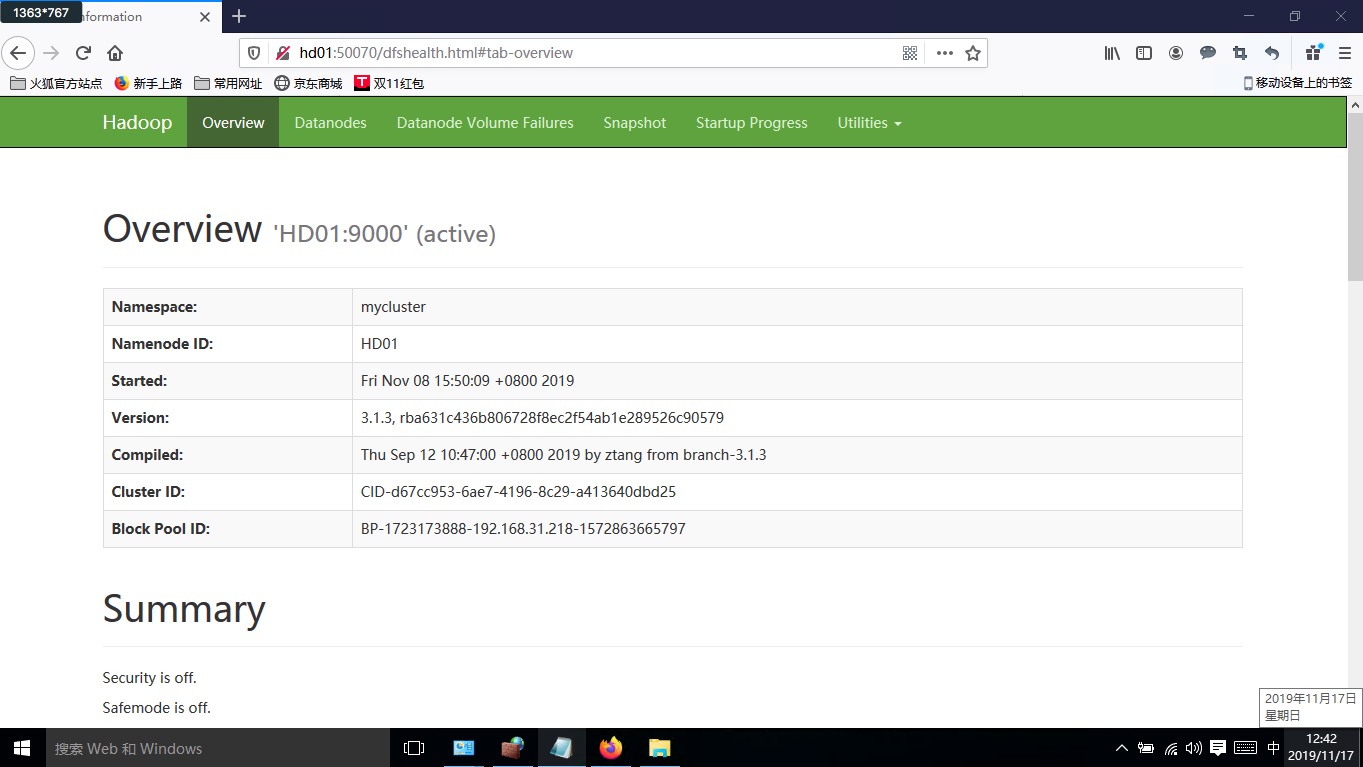
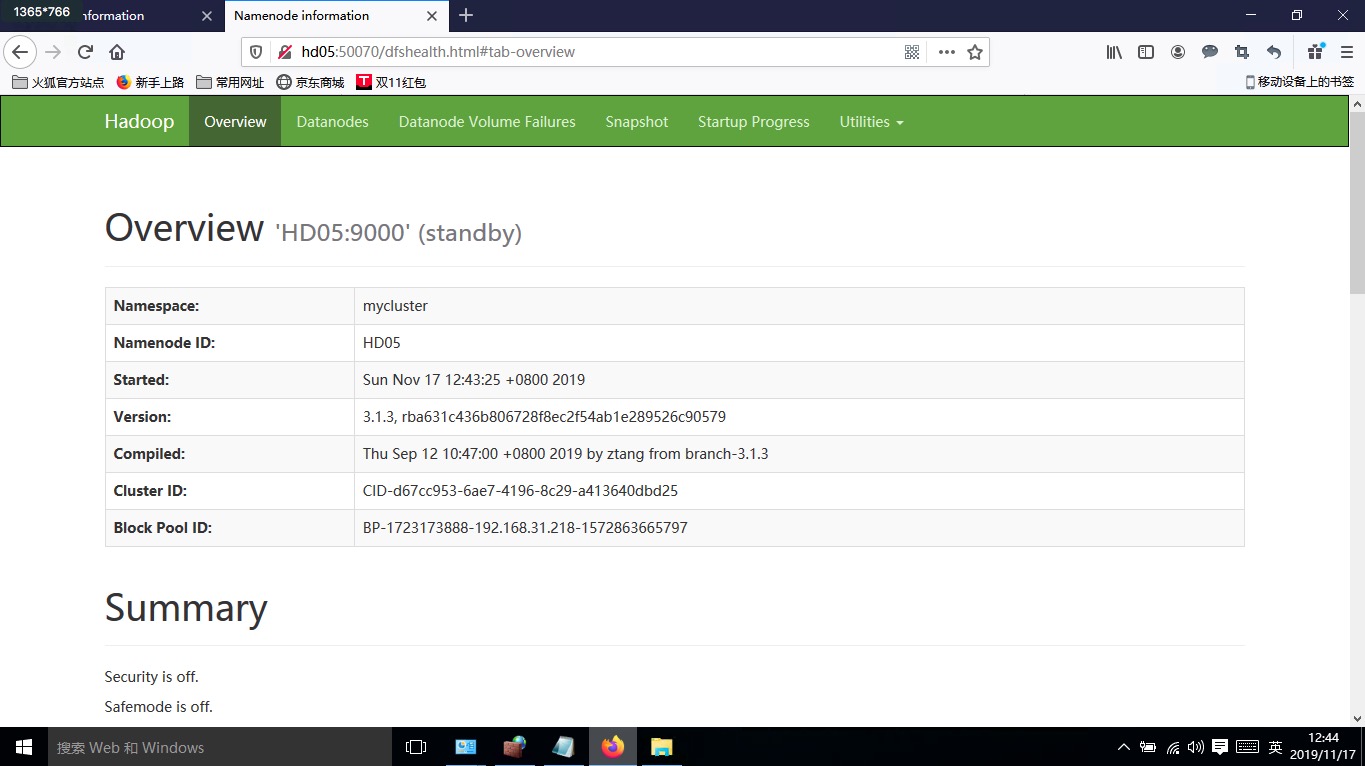
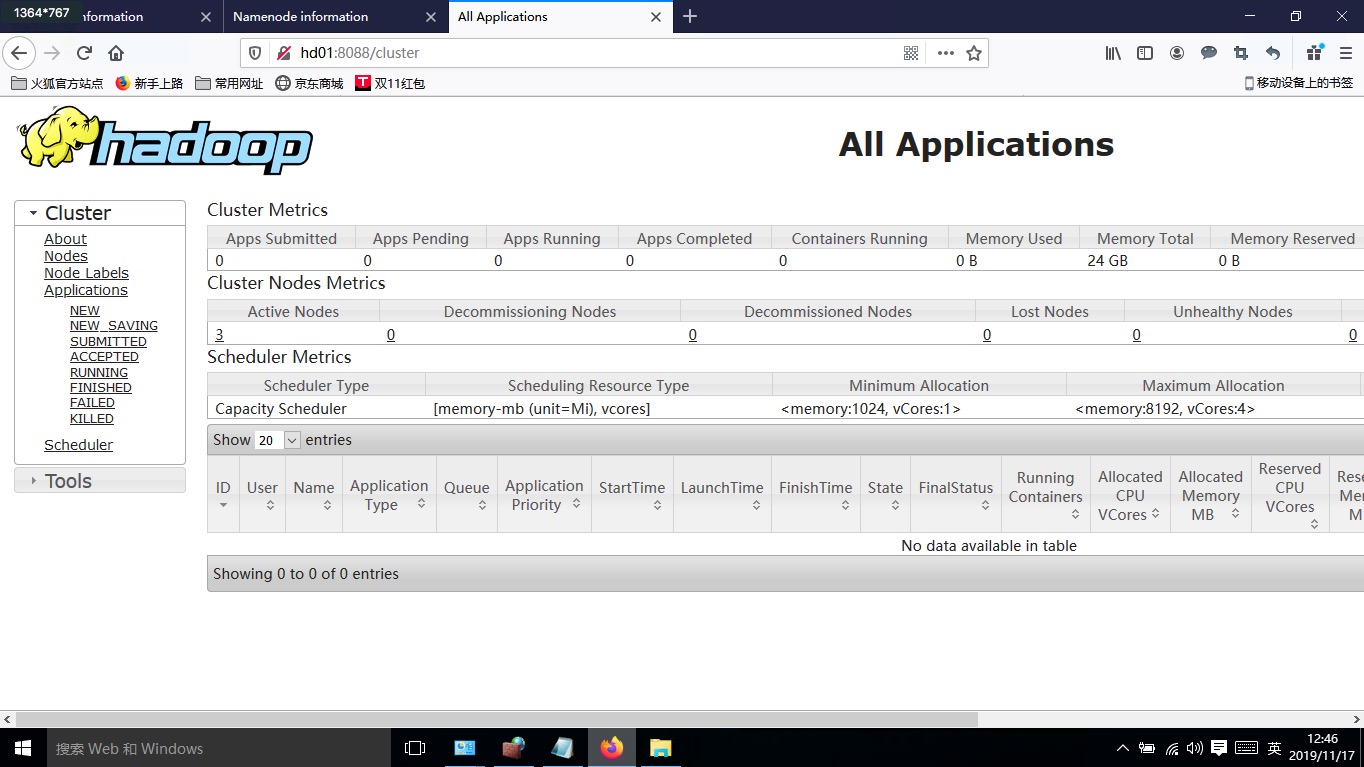
8、验证namenode、resourcemanager
在浏览器输入http://HD01:50070 ,http://HD05:50070, http://HD01:8088
五、各服务总结
